
Як цифри стають контентом: журналістика даних і її (не)розважальні грані
Марина Кравчук
Опубліковано: 11-03-2024
Розділи: Нові технології медіа, Стандарти якісної журналістики.
0
Дата-журналісти створюють матеріали, які захоплюють візуально, вражають об’ємом опрацьованої інформації і розповідають історії, які не мають права бути проігнорованими. Чому журналістика даних стала трендом у медіа? Чим вирізняється тематика дата-журналістики у США? І як маніпулюють за допомогою журналістики даних?
Раніше ми вже писали, що таке журналістика даних і з чим її їдять. Сьогодні додамо декілька штрихів, які дозволять побачити це явище об’ємніше.
Тренд чи традиція: повернення до історії дата-журналістики

Джерело: The Guardian
Найпершим матеріалом журналістики даних вважається дослідження The Guardian 1821 року (ще перше число газети!), в якому зібрали усі дані про кількість учнів та вартість їхнього навчання у школах Манчестера та Солфорда. Тоді вперше написали про те, скільки учнів отримали безкоштовну освіту і скільки бідних дітей було в місті. За офіційними оцінками вважалося, що безкоштовну освіту здобувають 8000 дітей, однак виявилось, що їх було близько 25 000. The Guardian підкреслюють, що це було “використання даних для боротьби за гідну систему освіти”.
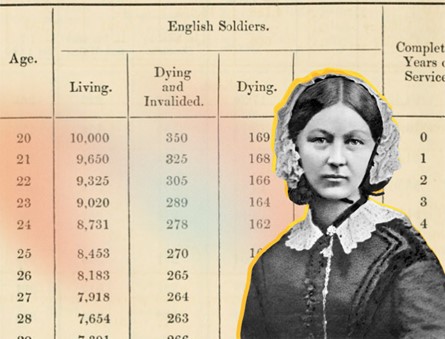
Флоренс Найтінґейл
Ще один приклад – 1858 р. Флоренс Найтінґейл створила дослідження, присвячене аналізу стану і щорічних втрат британської армії. На 54 сторінках матеріалу авторка наводить велику кількість даних, переведених в таблиці та діаграми. Основою для матеріалу стали “сирі” дані, отримані з відкритих джерел. Тоді новаторство Найтінґейл полягало не у використанні таблиць, а у підході до опрацювання даних. Таким чином авторка оформила прозорий матеріал, який кожен читач за бажання може перевірити на достовірність.
Як працює журналістика даних
Які потреби авдиторії закриває дата-журналістика, або чому вона стала трендом у медіасередовищі
- По-перше, журналістика даних спрощує розуміння складних питань чи проблем шляхом аналізу та візуалізації даних. Тоді пересічні реципієнти можуть легко споживати тексти зі сфер, у яких вони зовсім не розумілися раніше.
- По-друге, журналістика даних дозволяє виявляти та аналізувати тенденції та патерни у суспільних явищах. Це стосується різних соціальних проблем, для яких медійники можуть пропонувати шляхи вирішення або спонукати до цього читачів.
- По-третє, такі матеріали допомагають читачам відокремити факти від спекуляцій, оскільки базуються на об’єктивних даних, які кожен охочий зможе перевірити. Але не треба мати щодо цього ілюзій. Авдиторією можуть маніпулювати навіть за допомогою достовірних фактів, використовуючи їх у потрібний час і в потрібному місці.
До прикладу, матеріал американського журналу Global Finance “Poorest Countries in the World 2023” (“Найбідніші країни світу 2023”) заслуговує на увагу як демонстрація маніпуляцій в матеріалах дата-журналістики.

Джерело: Global Finance
У матеріалі читаємо, що, зокрема, війна в Україні погіршила і так погане становище цих країн. Так західні медіа несвідомо чи свідомо перекладають провину на Україну, навіть не згадуючи Росії, яка на неї напала. Тому часто маємо матеріали, які ґрунтуються на даних, але у заголовках чи в самих текстах медійники зміщують акценти, поширюючи стереотипи, маніпуляції чи пропаганду.
Або, наприклад, візуалізація статистики смертей серед обох сторін ізраїльсько-палестинського конфлікту, яку опублікували в The New York Times у жовтні 2023 року та яка була певною мірою маніпулятивною, оскільки чимало людей сприйняли її як виправдання дій терористів ХАМАСу і засудження відповіді Ізраїлю.
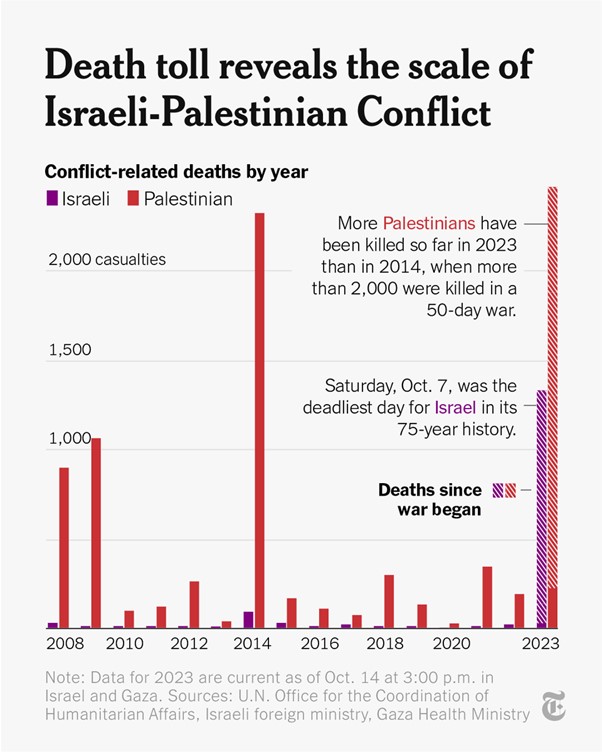
Джерело: The New Your Times у X

“Нищівний графік, і він сягає тільки 15 років тому”. Джерело: Ben Goggin у X

Вау, жахливо, здається, ХАМАС повинен ЯКНАЙШВИДШЕ звільнити цих заручників. Джерело: Joe Colangelo в X
Ізраїль використовує ракети, щоб захистити свій народ, Хамас використовує людей, щоб захистити свої ракети. Джерело: Linor Nachmany в X
Навіть одна і та ж візуалізація, що ґрунтується на об’єктивних даних, може викликати протилежні думки у читачів. Тому у дата-журналістиці так важливо не тільки подати дані, але й правильно пояснити їх. Звісно, якщо маніпуляції і пропаганда не мета медіа.
Базові типи журналістики даних
Журналіст та дослідник даних Ендрю Флаверз виділяє 6 основних типів історій (вони ж методи) журналістики даних:
Новизна – це коли вже самі дані є готовою історією, тобто коли з’являються дані, яких раніше не було, або дані, яких, ймовірно, не бачив читач. Флаверз називає цей вид винятком, який лише підтверджує правило. Дослідження The Guardian про кількість учнів, які навчаються безкоштовно якраз було цим типом дата-журналістики, оскільки цифри говорили самі за себе.
Викид – найпоширеніший тип дата-журналістики. У статистиці викид – це те, що виділяється із загальної вибірки. Заголовки, що містять слова найкращий, найгірший тощо – яскраві представники викиду. Такі тексти швидко захоплюють увагу читачів. Прикладом є матеріал The Economist “By the numbers, Lionel Messi is European football’s best scorer ever” (“Згідно з цифрами, Ліонель Мессі є найкращим бомбардиром європейського футболу”).
Архетип – історія чогось типового. Тут важливим є застереження: не спрощувати, а намагатися розглядати все у контексті. До прикладу, матеріал Бена Каслмена “The Poorest Corner Of Town” (“Найбідніший куточок міста”), який він створив після новин про місто Фергюсон (штат Міссурі). Журналісти подавали все так, ніби Фергюсон – це виняток у сенсі расової економічної нерівності. Каслмен же у своєму тексті доводить, що це не так: багато міст США мають таку ж проблему, тому Фергюсон не більш бідний чи нерівний, ніж інші.
Джерело: FiveThirtyEight
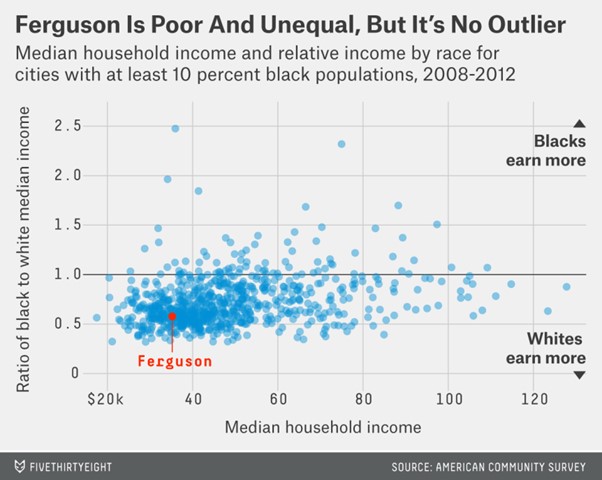
Джерело: FiveThirtyEight
Прогноз – його яскравим прикладом є проєкт 538 (раніше FiveThirtyEight) американського статистика Нейта Сільвера, який прогнозує результати виборів, спортивних матчів. Відомим він став завдяки тому, що зміг правильно спрогнозувати переможця у всіх штатах під час президентських виборів 2012 року. Прoєкт популярною мовою описує статистичні моделі у різних галузях людського життя – від економіки до шахів та пташиного грипу.

Джерело: FiveThirtyEight
Прикладом того, як статистика перетворюється на прогноз є матеріал Меґґі Керт “Suicide Prevention Could Prevent Mass Shootings” (“Запобігання самогубствам може запобігти масовій стрілянині”, в якому авторка наводить різні дослідження, які підтверджують таку кореляцію: зазвичай до масової стрілянини схильні ті, хто схильні до самогубств. У тексті наведені слова головної психологині Секретної служби США Маріси Рандаццо: “Ми навіть спілкувалися з кількома людьми, які намагалися вбити себе, але не зуміли, а потім здійснили напад, оскільки сподівалися, що поліція вб’є їх”. Тому Керт спрогнозувала, що red flag laws (закони про червоні прапорці) можуть стати корисним інструментом для боротьби з масовою стріляниною, яка по суті є публічним насильницьким самогубством.
Тенденція – її зазвичай визначають завдяки алгоритмам. ProPublica у матеріалі “Machine Bias” (“Упередження машини”) проаналізували COMPAS – програмне забезпечення у США для суддівських рішень щодо обмеження волі звинувачених – яка ймовірність того, що конкретна людина ще раз вчинить злочин протягом, наприклад, наступного року. Якщо ймовірність висока, то суддя ухвалить рішення про обмеження волі.
ProPublica отримали дані про рішення суддів та параметри алгоритму. Аналіз показав, що при однакових умовах темношкірі особи отримували менш сприятливий прогноз порівняно з білими. Це означає, що програмне забезпечення було упередженим стосовно темношкірих.
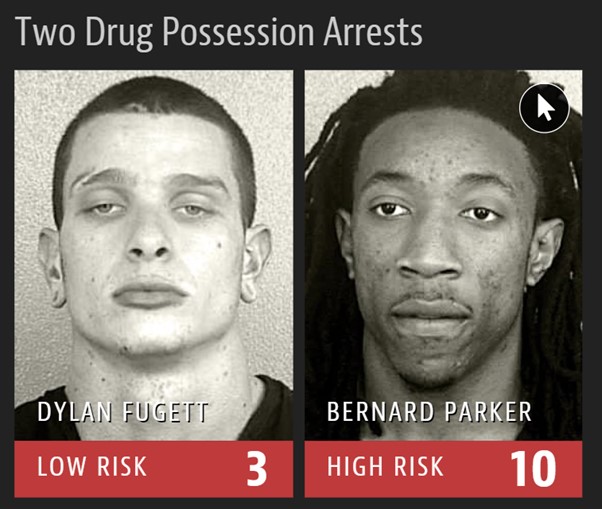
Джерело: ProPublica
Розвінчування – ще один класичний тип дата-журналістики. Оскільки нас щодня оточують стереотипи, упередження і міти, медійники можуть використати це для створення контенту. Це можуть бути матеріали на резонансні теми, але як приклад наведемо “Are Pop Lyrics Getting More Repetitive?” (“Тексти попмузики більше повторюються?”) від The Pudding.
Автор Колін Морріс вирішив перевірити, чи має сенс упередження, що з роками лірика попмузики стала нуднішою та повторюванішою. Для цього він взяв за останні 50 років перші десятки пісень, що входили в чарти – завантажив їхні тексти і перевірив кожен текст, чи справді в ньому є багато повторів, використавши алгоритм архівації даних ZIP, який шукає у файлах однакові фрагменти і кодує їх одним символом. Щo більше таких однакових фрагментів (тобто щo більше повторів у файлі) – тo більше цих символів буде.

Джерело: The Pudding
Таким чином можна побачити, на скільки відсотків стискався файл тексту пісні, до прикладу, 60-х чи 70-х років і на скільки відсотків стискається файл сьогоднішнього хіта.
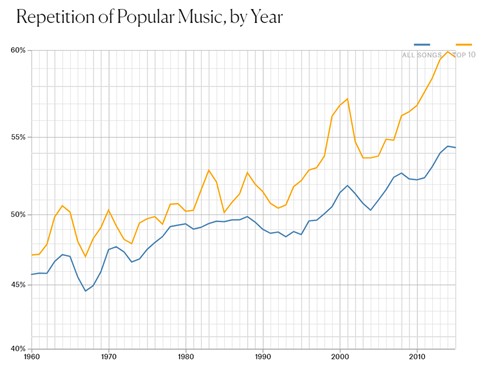
Із графіка зрозуміло, що дійсно треки стали повторюватися на 22% більше. Так Морріс шляхом аналізу даних підтвердив упередження про одноманітність сучасної музики.
Журналістика даних – це win-win situation для медійників і читачів. Читачі мають змогу споживати нетривіальний контент, який змушує або замислитися над проблемами суспільства (для США найтиповішими є питання расової нерівності та масової стрілянини), або допомагає навпаки від них відволіктися яскравими та інтерактивними лонґрідами. Журналісти у свою чергу отримують більшу довіру і фідбек від авдиторії.
Дата-журналістика дозволяє розкривати важливі (і не дуже) теми максимально френдлі для читачів, не лякаючи їх гігабайтами даних, а подаючи усе з необхідною візуалізацією. Головне не потрапити в пастку і не забути, що під шарами привабливої (і змістом, і виглядом) історії може ховатися неправда і брехня: ненавмисна чи навмисна.
Марина Кравчук, студентка факультету журналістики ЛНУ ім. І.Франка

